
What’s wrong with databases?
I won’t try to sell you the idea that stored procedures are the best and that everybody needs to throw away all their ORM code and move to the database world. I believe that every team has to choose the best tool that not only helps them to solve their problem and but also makes them more productive.
Whether you landed on a project with many stored procedures, you’re a DB geek or you simply consider stored procedures the right tool for the job, you will face many challenges if you want to improve your team’s productivity.
What I’ve noticed is that sometimes, even when it makes sense to use a stored procedure, a developer won’t go that way just because she wouldn’t feel productive using that technology. This attitude is usually related to one or more of these problems:
A shared database
Teams tend to have only one SQL Server with several versions of the same database, e.g. Dev, Test or CI.
So, if one developer makes a change in the DEV database, it will affect others immediately. Some teams will try to mitigate this problem by altering the database as little as possible, and notifying everyone when they do.
Lack of Source control
Maybe you’ve never thought about this, but source control plays an important part in your team’s productivity. The easier you can integrate your code, track changes or switch between tasks the more productive you are going to be. Very few teams put their database under source control, how would you do that? Don’t worry, we’ll get there.
No debugging
Are you telling me that people debug procedures? Yeah… I think only two developers do that, but it’s possible.
Being productive
Here are some tips and tools that have helped my team to stay productive when working with databases.
The database is part of your code
Even if you don’t use stored procedures, your tables definitions are part of your code. Ok, you might say “I’m a code first developer, I don’t care about the database” and that’s fine, this post won’t help you at all. But if you are a “database first” developer, the table definition should be part of your code. If you add a new field to a table, you will need to create a branch, add that new field to the table definition and commit everything into the same branch as the code using that new field. The benefit is quite obvious. When your PR is accepted not only will your code be merged but you will also get that new field in the database.
How can this be accomplished?
I found in Visual Studio the solution to this problem. Let’s take a look at it.
Creating a DB Project
Let’s use our well-known Northwind database as an example. Just go to Visual Studio, click “New project” and look for “SQL Server Database project”.
Import your current database
I bet you already have a database, if so, you will be able to import the whole database definition using the import tool.

Then you will need to setup the database connection and import settings. Let’s keep this simple.
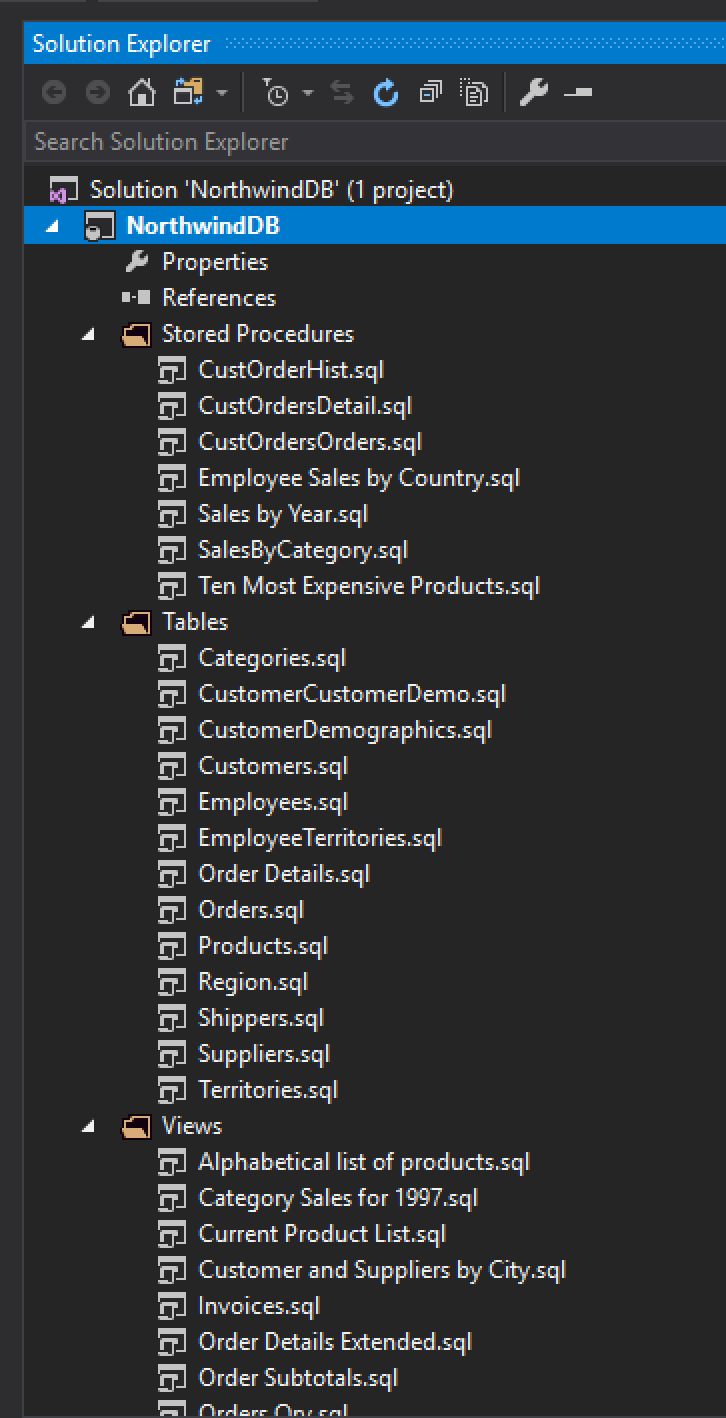
Voilà! You now have your database ready to be committed into your repository.
Decentralized
Perfect, we have our database in source control, now what?
The next thing you must have is one database per developer where she can have the freedom to update/recreate it when needed. You can accomplish this in three ways, ok there might be more ways but these are the three I recommend:
One database in a shared server
This could be the easiest solution if you already have one server used by all developers. You could use a naming convention to identify each database, something super smart such as <MyProject>Dev<DevName>.
Pros
- There is not much to setup. Just create one database per dev.
- Collaboration. Devs can access each other database making it easier to collaborate.
Cons
- If you are not using a shared server right now, you might need to setup one server and think about security (VPNs and things like that).
- It might be a slower experience for the developer compared with a local environment.
- One developer might slow down your server if she is executing some heavy task.
LocalDB
LocalDB is a lightweight version of the SQL Server Express Database Engine that is targeted for program development.
You might not know it but if you have Visual Studio installed there is a good chance that you already have LocalDB installed. You can check this out by opening the SQL Server Object Explorer.
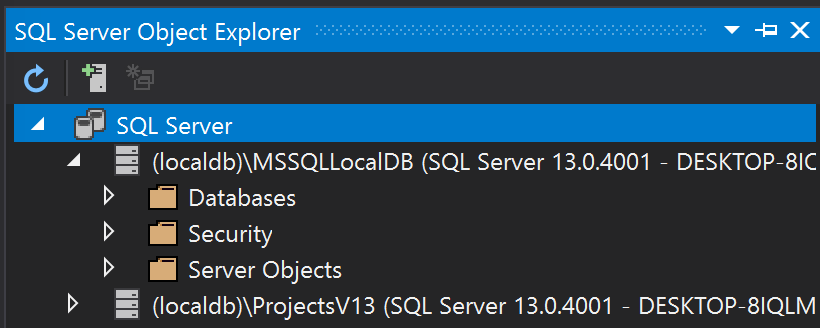
If you don’t find a LocalDB there you can see how to install it here. There are other versions you can install. For instance the full Microsoft SQL Server Developer Edition.
Pros
- Your localDB is already there, you just need to use it.
- It’s a local database, you won’t need a VPN or request access to a server.
- A local database will speed up your environment, especially for remote developers.
Cons
- Running a SQL Server process could be quite expensive for you computer, slowing down your development environment.
Local Server on Docker
This solution is similar to the localDB one, but better suited if you use Mac OS. When running Visual Studio in a virtual machine on Mac OS, running SQL Server in a Docker container (directly on the Mac OS) will speed up your virtual machine. I would strongly recommend this solution if you use Mac OS.
You can read about running SQL Server on Docker here.
You need data to work with
As each developer would have her own database, having data to create a useful and ready-to- use database becomes another very important piece of the project. It’s very easy to create all this data if you already have an existing database.
First, let’s create a Data folder where we’ll save all our insert scripts.
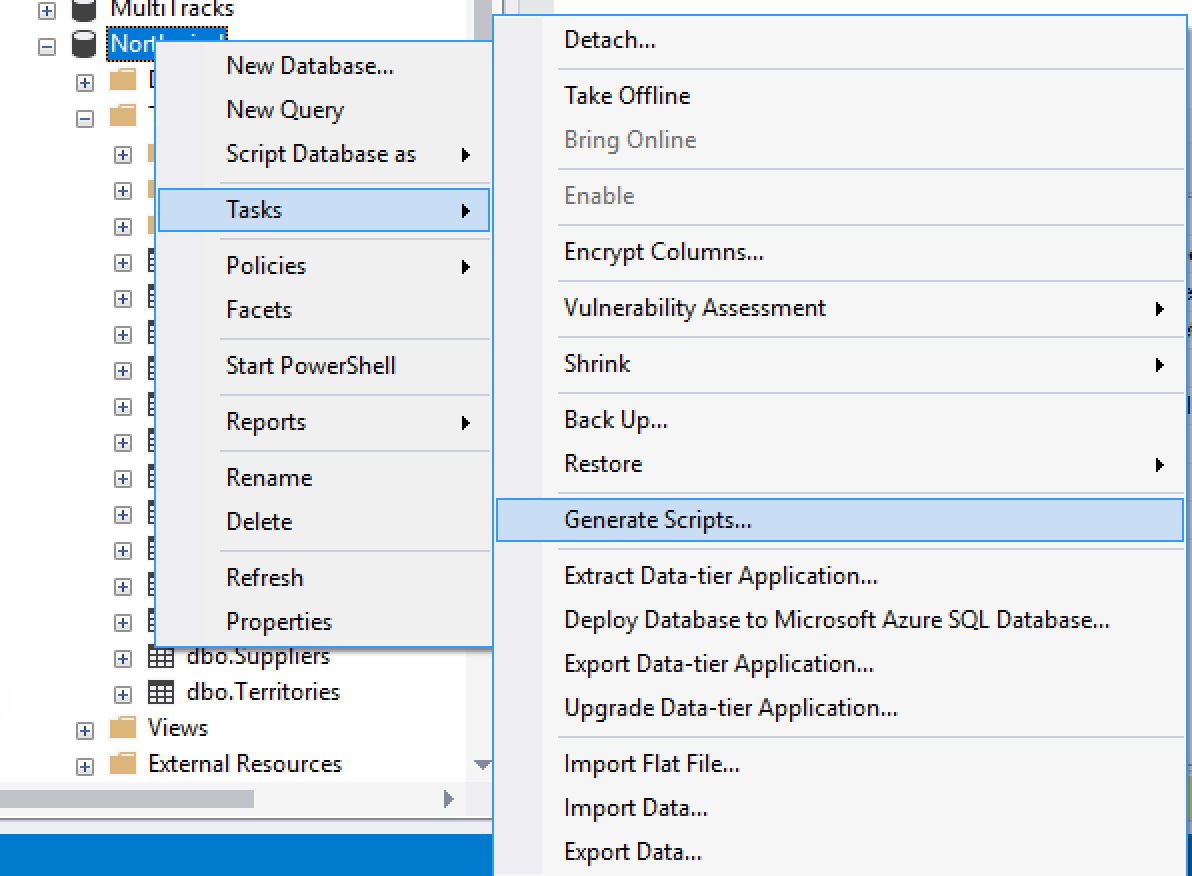
SQL Server Management Studio has a very cool tool to generate scripts, it is called… drum rolls… Generate Scripts!
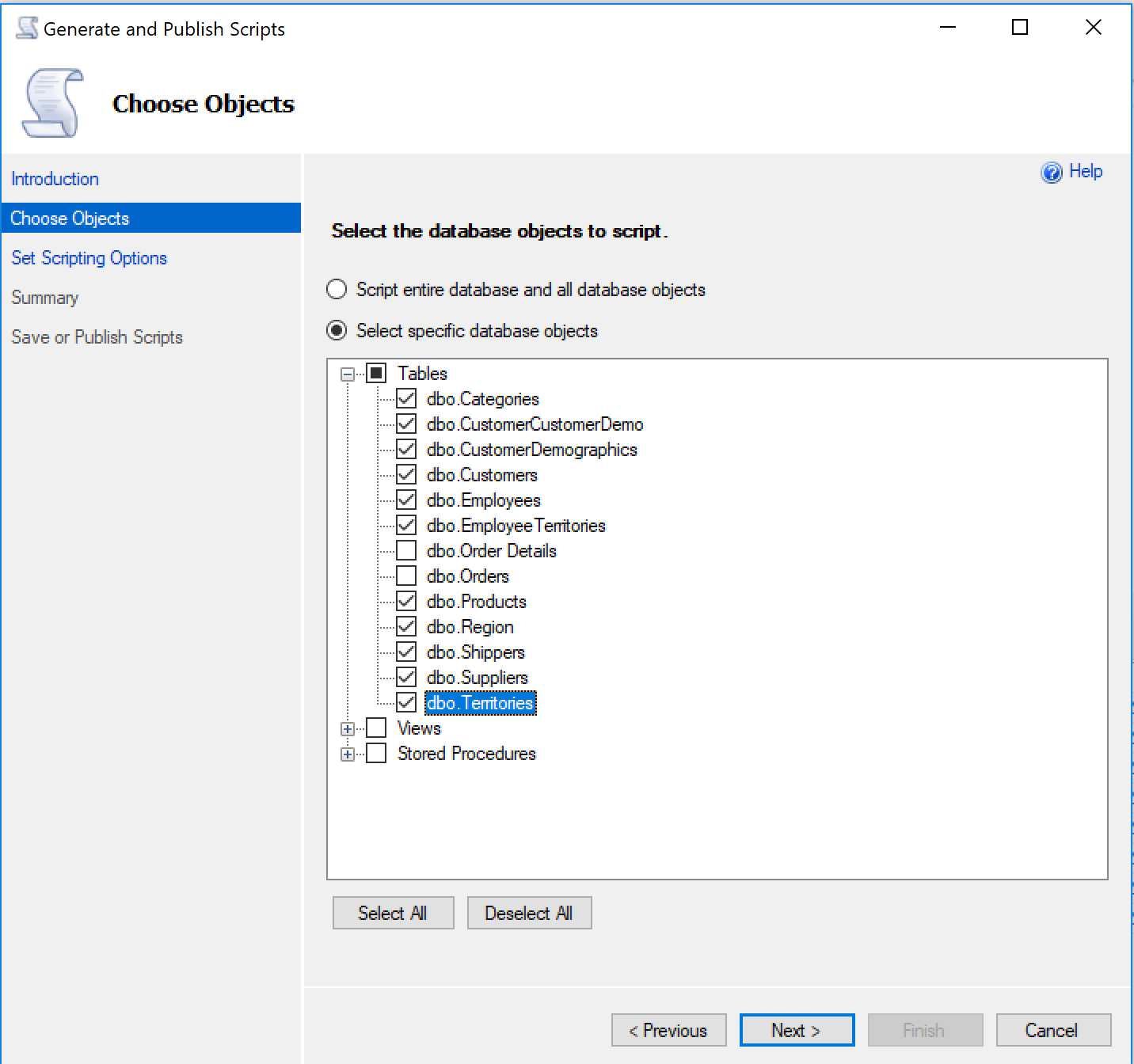
Once there, we need to pick the tables to generate.
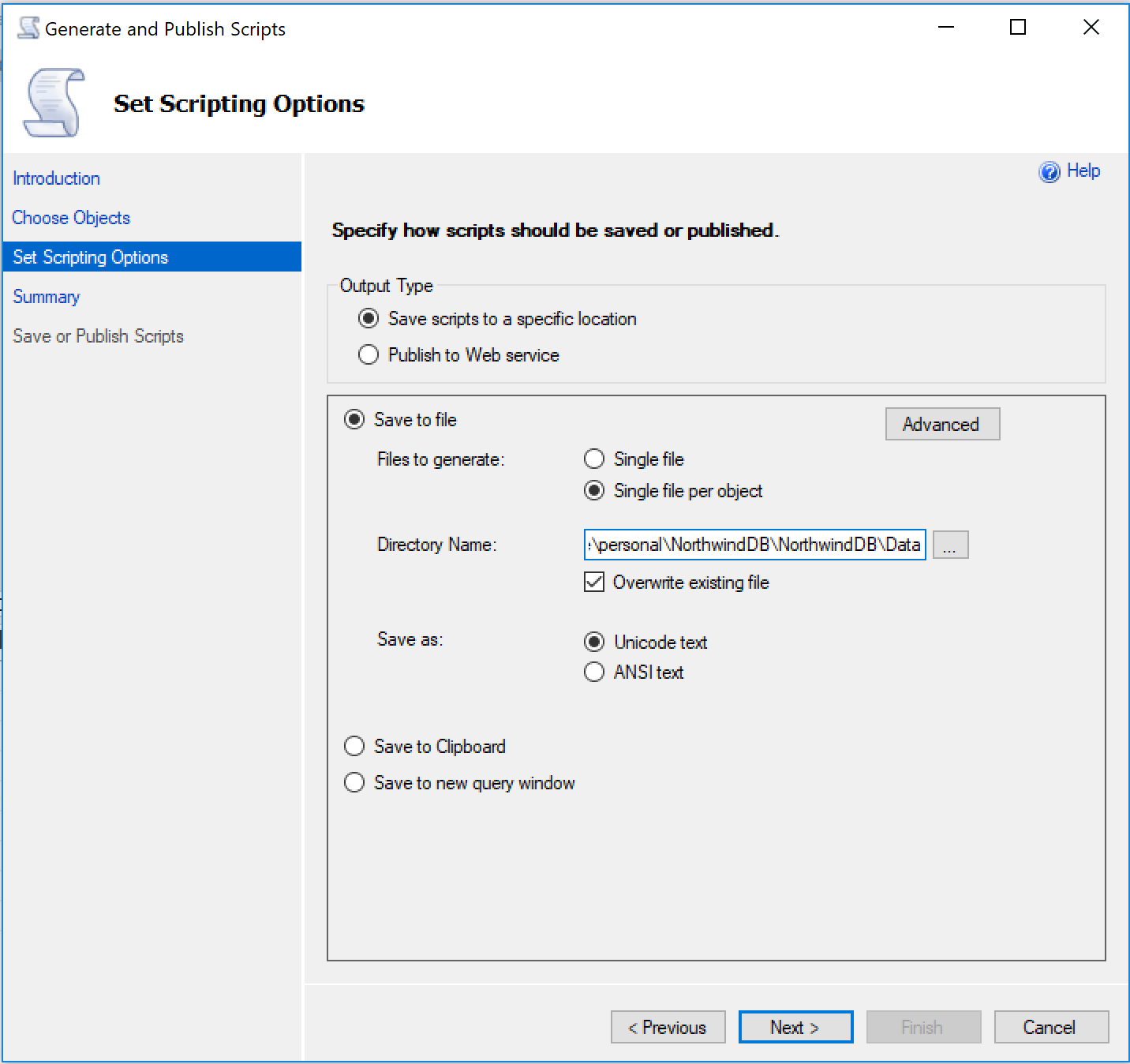
Then we select the location. We will need to enter the data folder we created on the SQL project.
We need to go to the Advanced option and indicate that we only want the data.
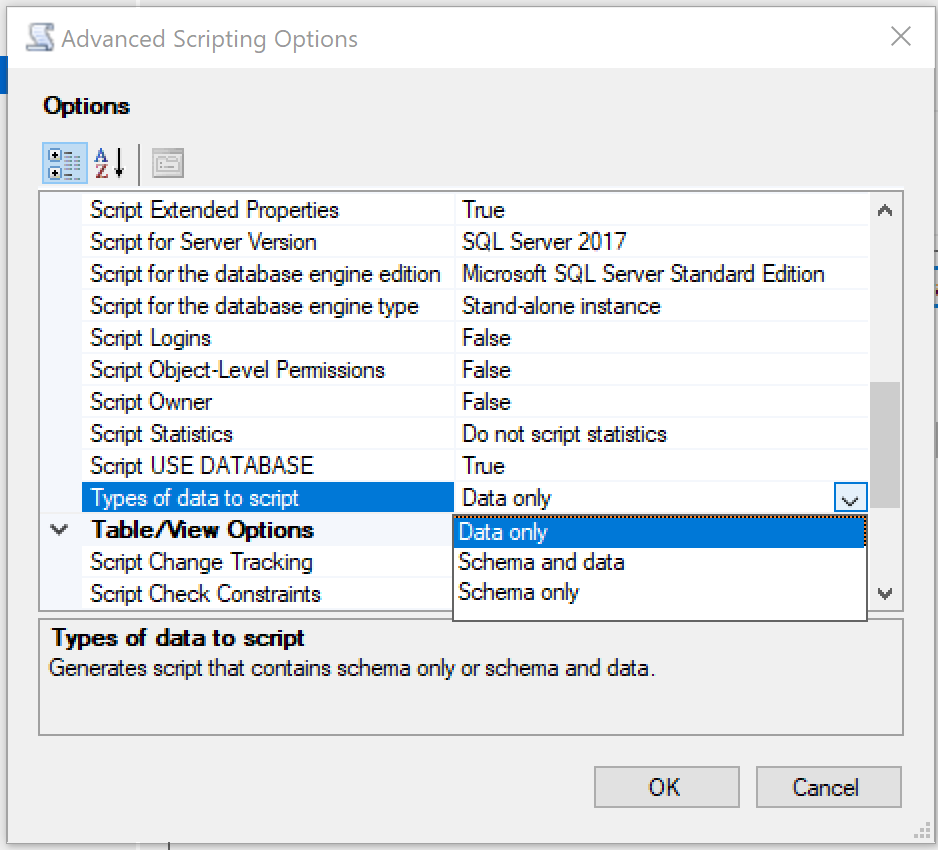
And we are done!
Now if we go back to the SQL Project we’ll see all the scripts we’ve just generated. Let’s include those files in the project.
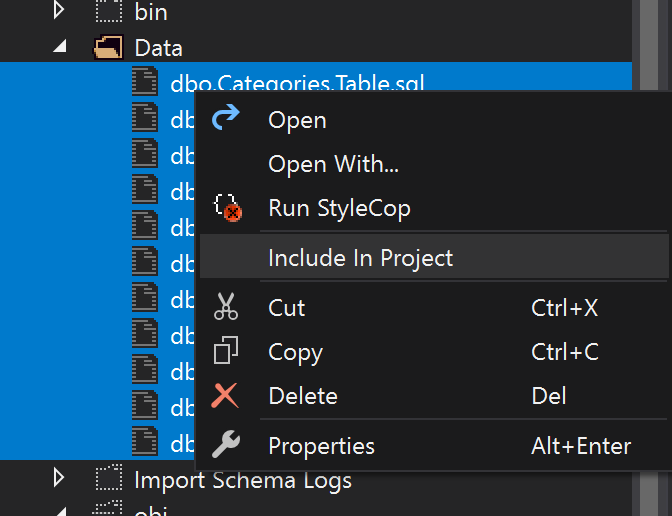
By default, when we include files in a project the Build Action is set to Build, but as these files are just insert scripts we need to set them to None.
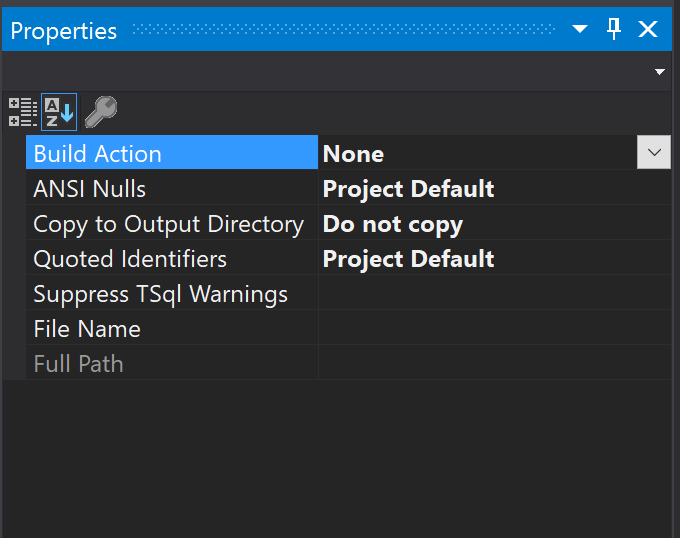
So, how do we make use of these scripts? We need to create a Post Deployment Script and include all these inserts there.
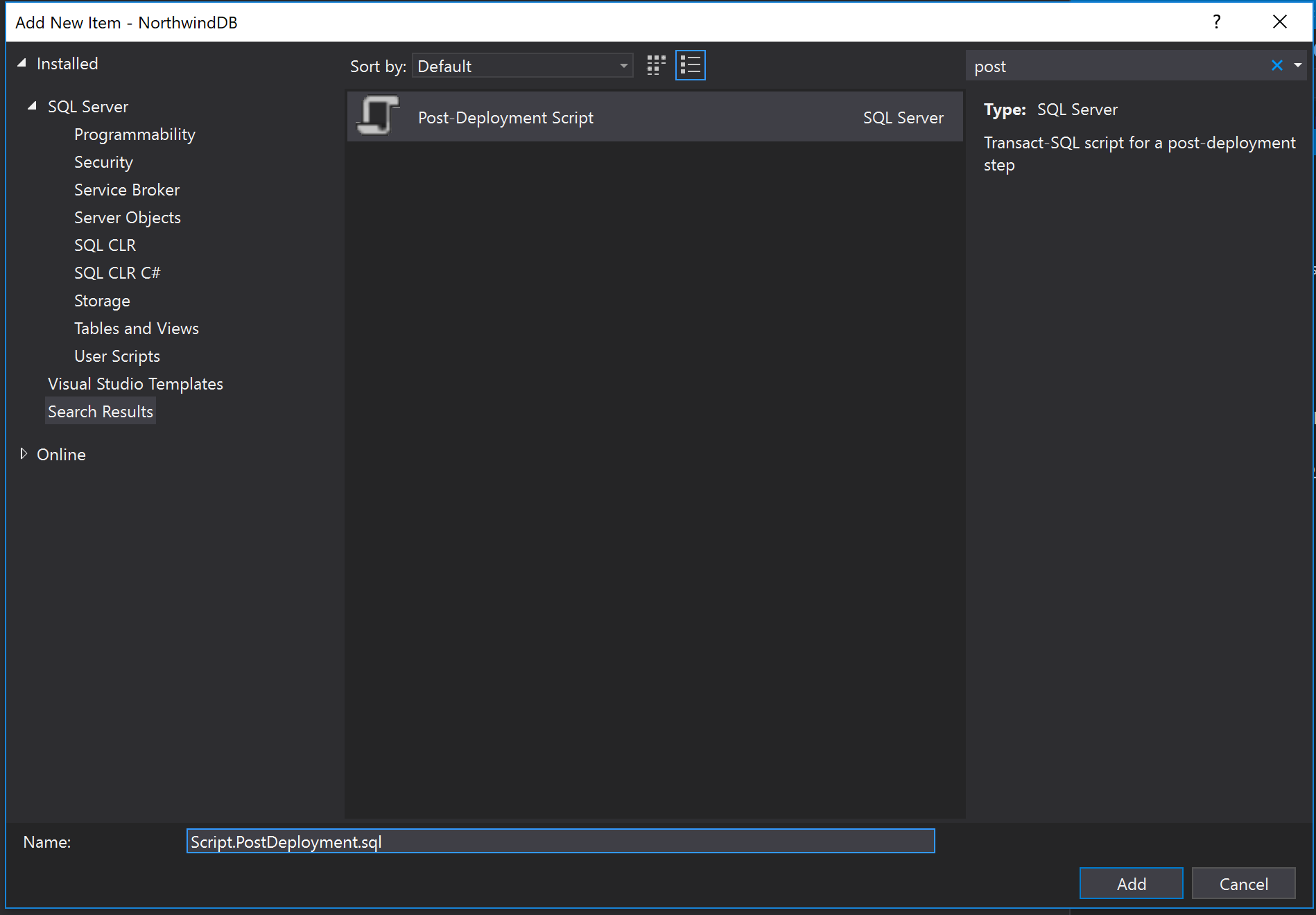
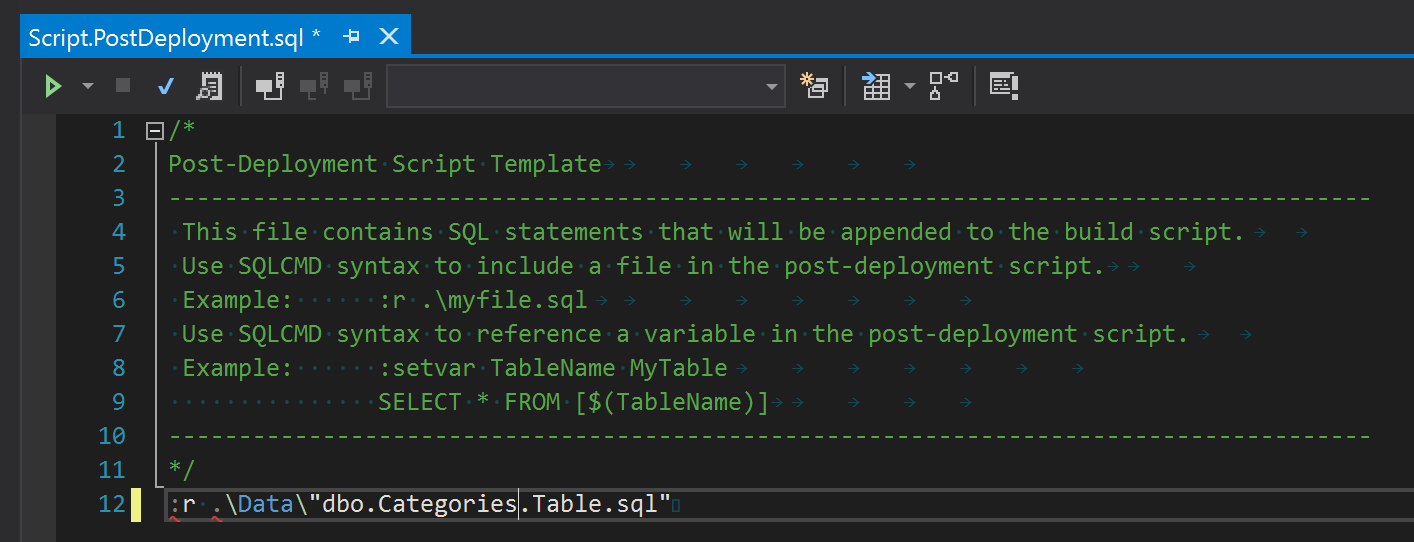
So now we can complete this file with all the insert scripts we created before.
DB Syncing
Perfect! We have a SQL Project, with our tables, stored procedures and even our test data! Now we have to use it.
Publish tool
Publish is the tool you would use to create the database from scratch. So let’s go to the publish option.
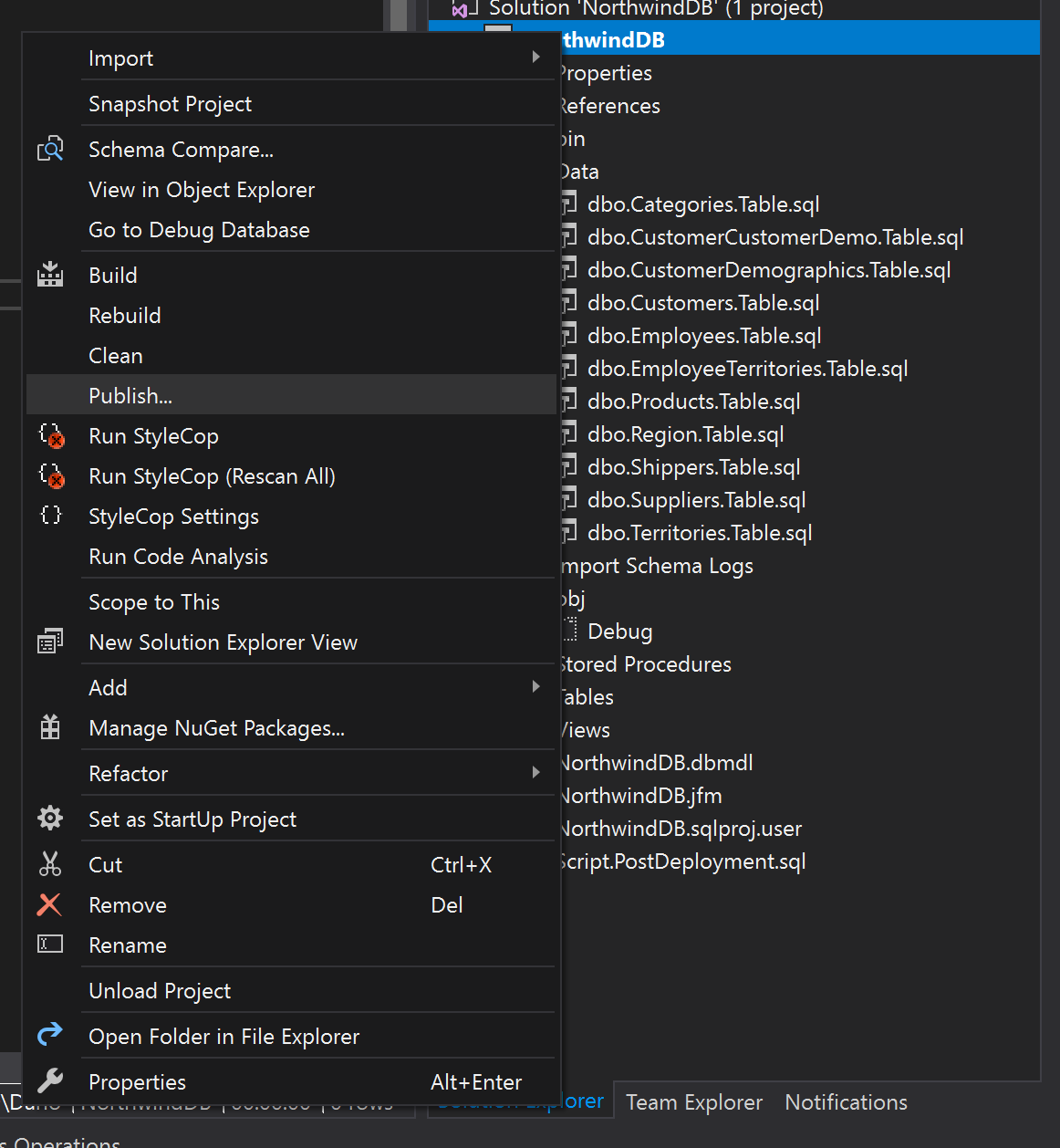
Once there, we just need to pick our connection string and the destination database.
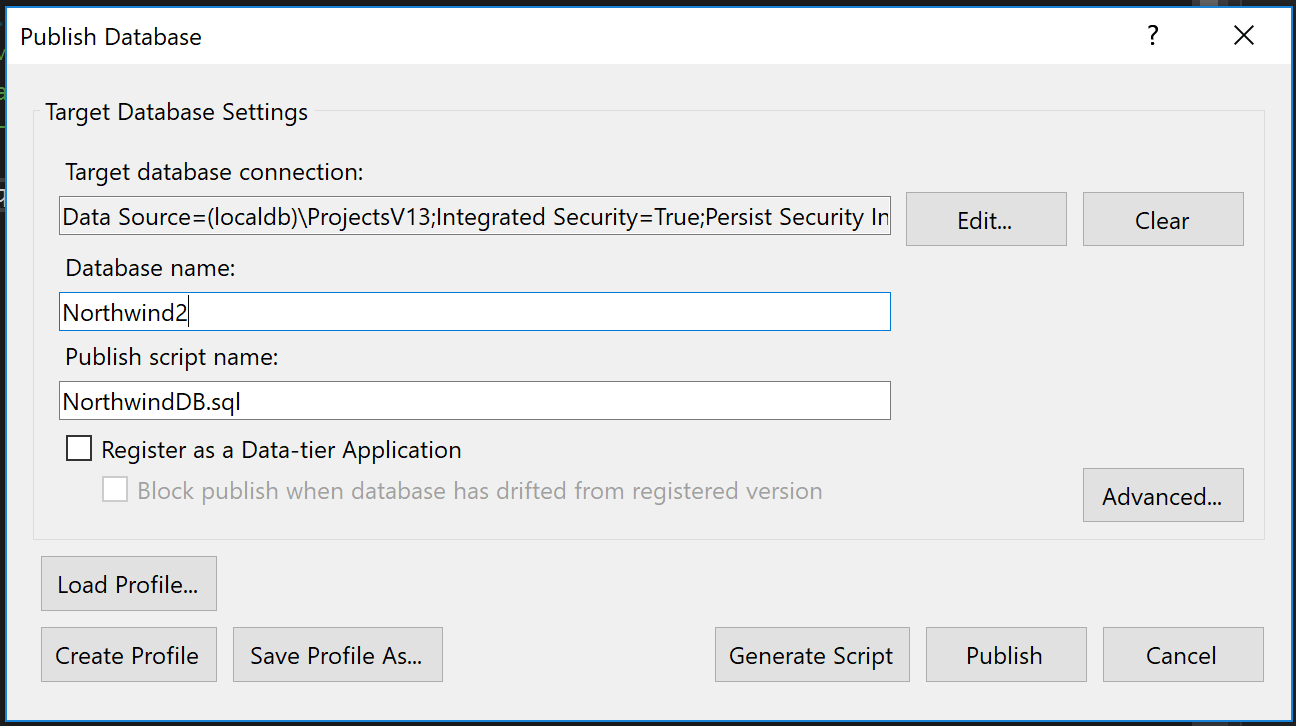
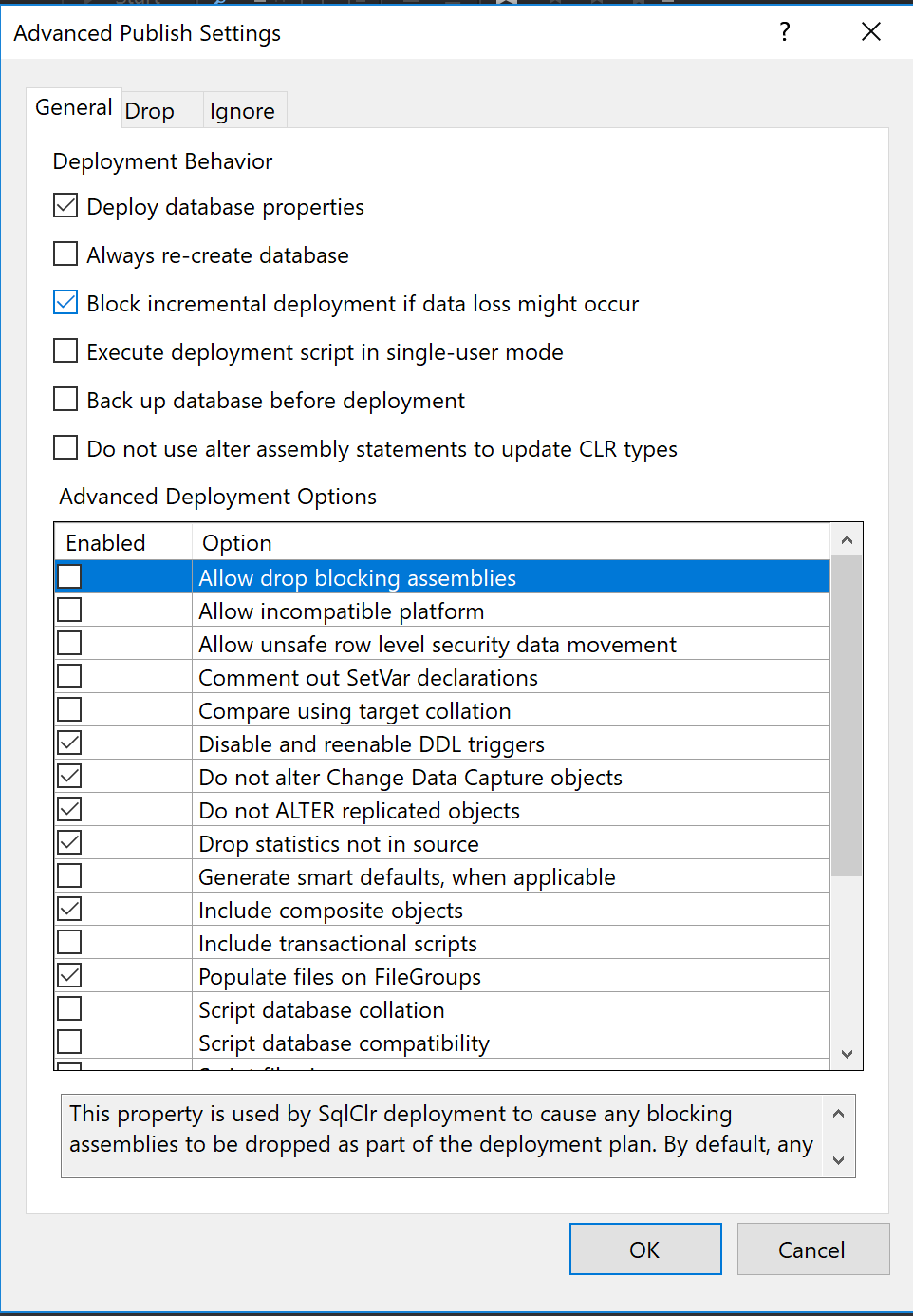
In the Advanced section there are some interesting options, like “Always re-create database” or “Block incremental deployment if data loss might occur”.
Then, just hit publish and voilà! You have a new database with all your tables populated and ready to be used!
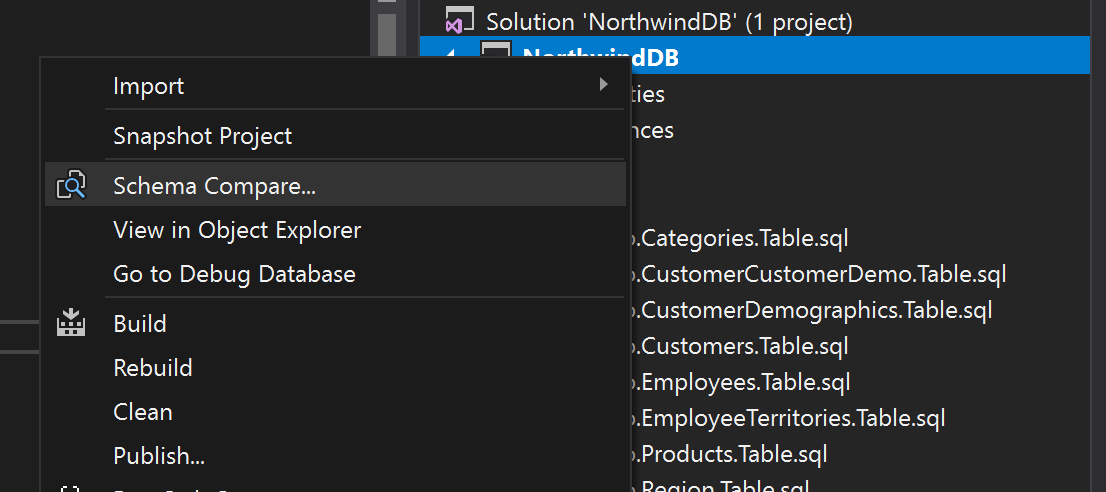
Schema Compare tool
Schema compare is the tool you would use day to day to compare and sync your SQL code with your database.
Once there, you will not only be able to see not only what objects are going to be changed but also what those changes are.
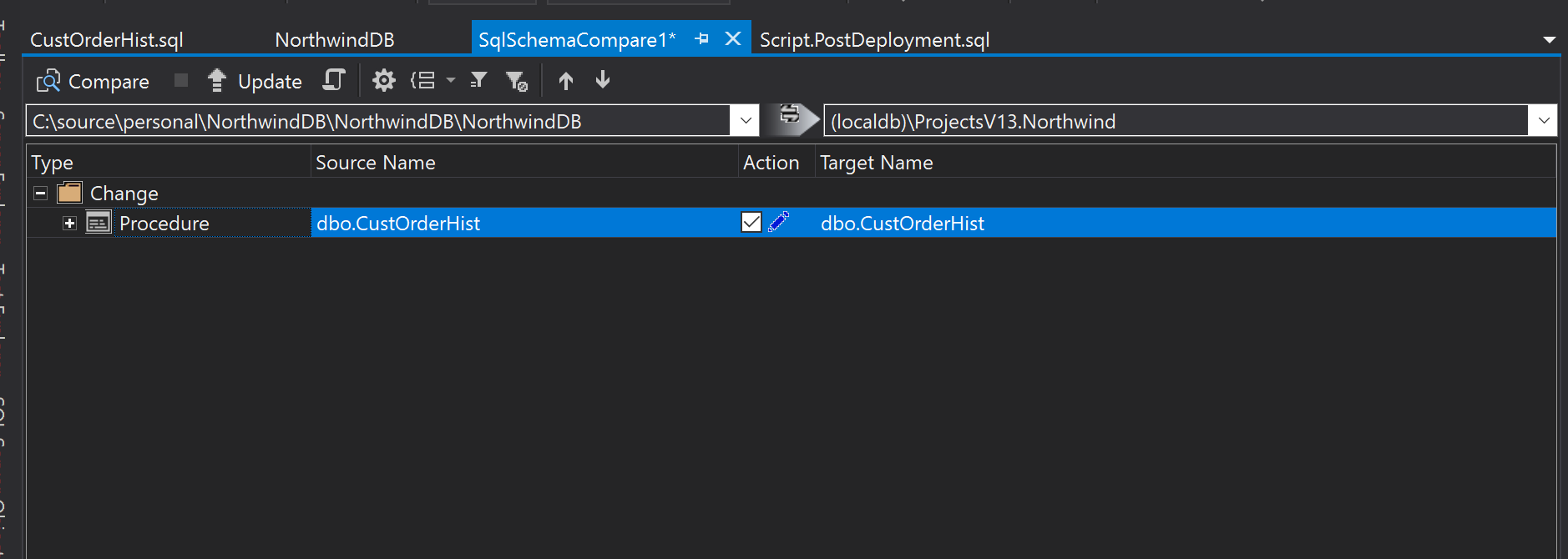
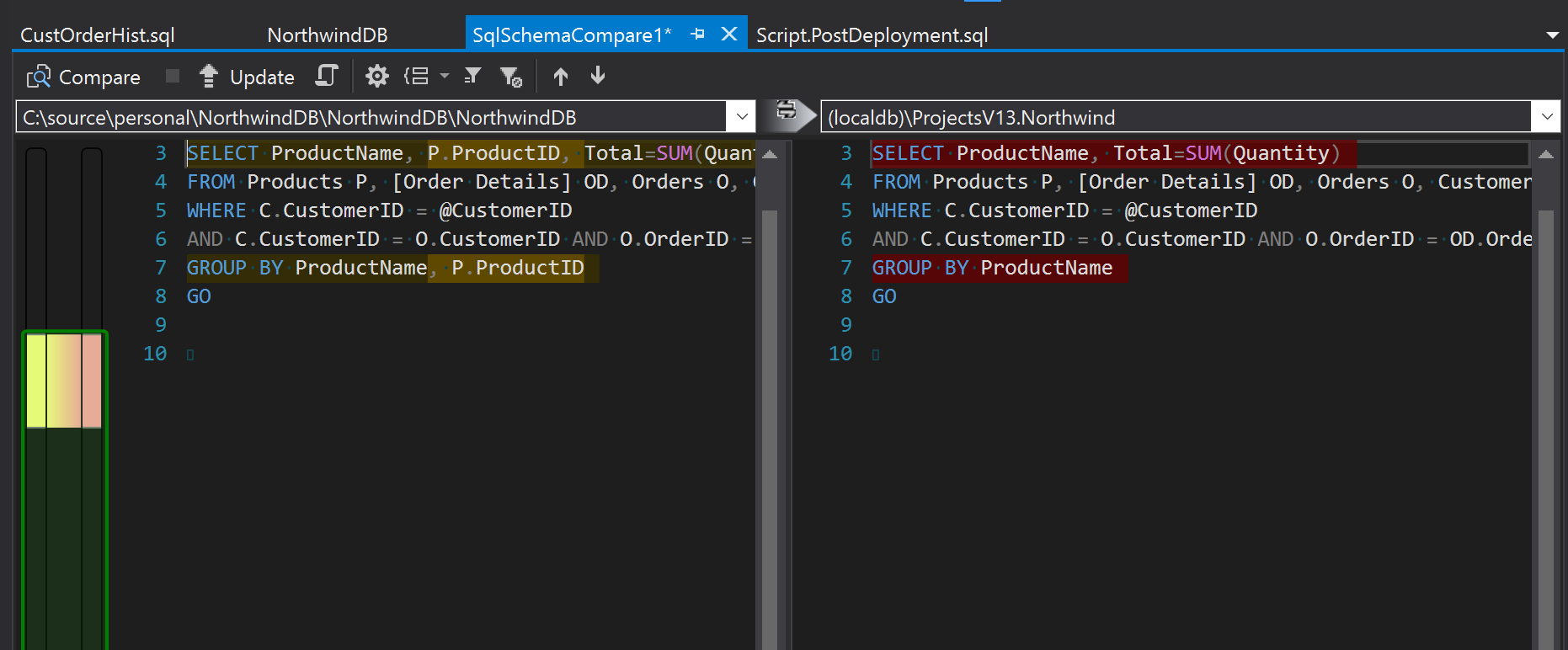
Before hitting “Update” you might want to go to the Schema compare options and uncheck “Block on possible data loss”. You would do this if you wanted to apply changes made in another branch even if data will be lost.
ProcUpdater
Schema compare is perfect at his job, it can create a database from scratch, create users, schemas, handle table and column renames, everything. But, it can also slow down your development process. The compare step might take up to 3 minutes and the Update itself another 3 minutes. If you do that ten times a day you would end up wasting one hour waiting for the DB to sync up.
So I created a small app called ProcUpdater (yes, I was inspired that day). ProcUpdate will watch your Stored Procedures folder and apply your stored procedures changes immediately. It can even apply all the stored procedures changes when you switch branches. It’s not perfect, it won’t apply table changes, but it could save you 1 hour a day!
CI
This workflow fits perfectly if you need to run integration tests in a CI environment. If you use a Windows based CI environment like AppVeyor you will be able to deploy your database in that environment every time you build a branch. You just need to run msdeploy.exe. It could be something like this:
msbuild "NorthwindDB.sqlproj" /p:Configuration=Release /p:Platform="Any CPU"
"C:\Program Files\IIS\Microsoft Web Deploy V3\msdeploy.exe" -verb:sync -source:dbDacFx="NorthwindDB.dacpac" -dest:dbDacFx="...",dacpacAction=Deploy,CreateNewDatabase=True'
Final words
I used to say that most of the time you can hide complexity but not remove it completely. If your project is using lots of stored procedures, we may not be able to remove that complexity (and we haven’t even talked about dealing with staging environments), but there are some tips and tools that can speed up the process and help make your team much more productive.