¿Cuál es el problema con las bases de datos?
“¿Cuál es el problema con las bases de datos?”. Esa fue la pregunta que nos hicimos en el primer post. Allí hablamos de las principales trabas al momento de trabajar con stored procedures, y sobre cómo comenzar a descentralizar nuestras bases de datos de desarrollo.
En este post vamos a hablar sobre cómo integrar tu base de datos en tu código fuente.
¿Muy largo para leer? !Mirá el video!
La base de datos es parte de tu código
Incluso si vos no usas stored procedures, las definiciones de las tablas son parte de tu código. Vos podrías decir: “Ok, pero yo trabajo code first, no me importa la base de datos”, perfecto, entonces este post no te va a ser de mucha ayuda.
Pero si vos sos un “database first” developer, las definiciones de las tablas deberían ser parte de tu código. Si vos agregás una nueva columna a una tabla, vas a necesitar crear un nuevo branch, agregar esa nueva columna en la definición de la tabla y commitear el cambio en el mismo branch donde vas a ser uso de la nueva columna.
El beneficio es obvio. Cuando tu pull request sea aceptado, no solo tu código va a integrarse, sino también el cambio en la base de datos.
¿Cómo podemos lograr esto?
Encontré que Visual Studio tiene la solución (o el proyecto :p) a este problema. Vamos a echar un vistazo.
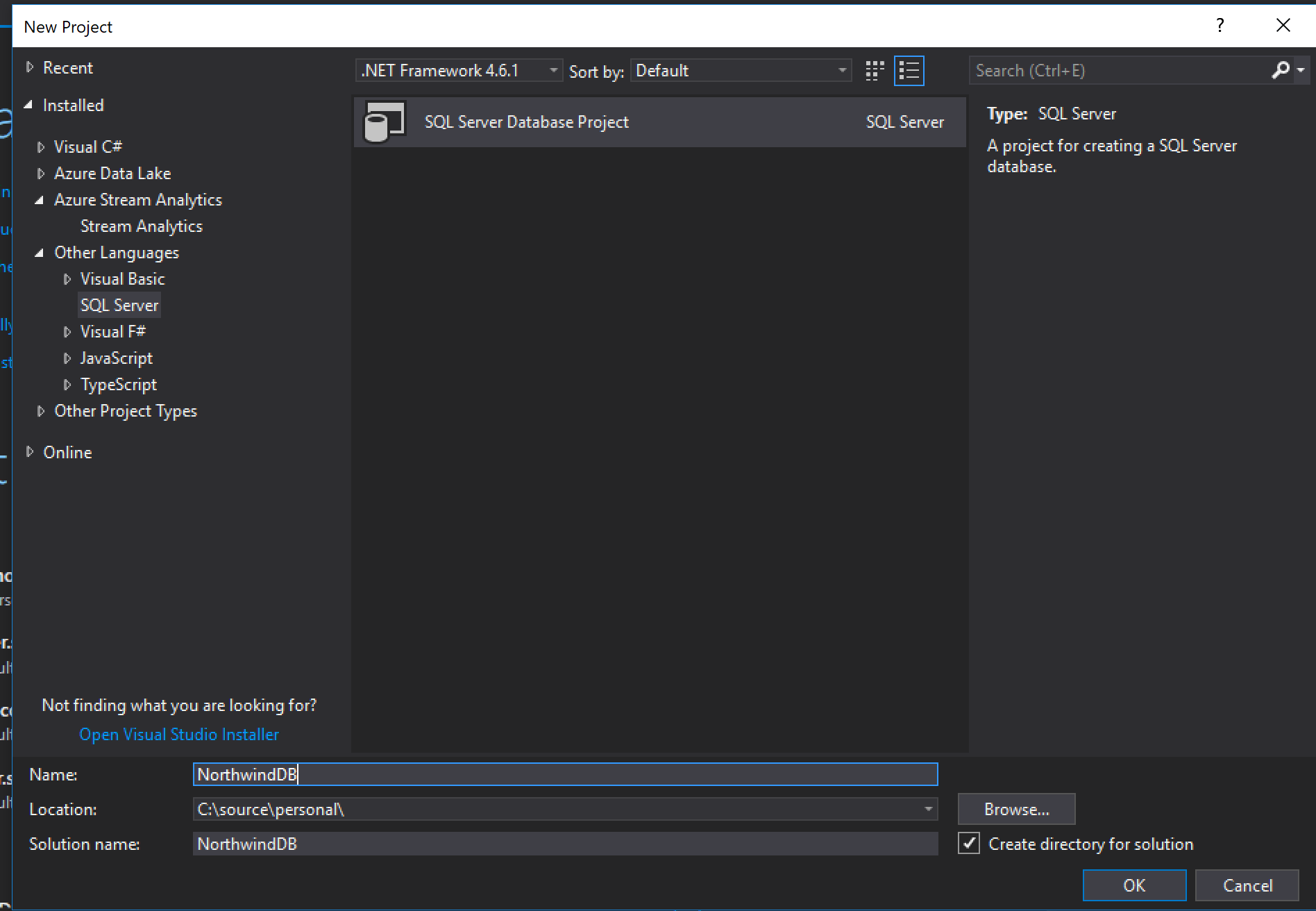
Crear un Proyecto de base de datos
Vamos a usar nuestra vieja y conocida base de datos Northwind como ejemplo. Ahora vamos a Visual Studio, elegimos “New Project” y buscamos la opción “SQL Server Database Project”.
Importar nuestra base de datos
Muy probablemente vos ya tengas una base de datos, entonces, vas a poder importar toda la definición de la base de datos usando la herramienta de importación.

Después, vas a necesitar configurar la conexión y la configuración de importación. Vamos a hacerlo simple:
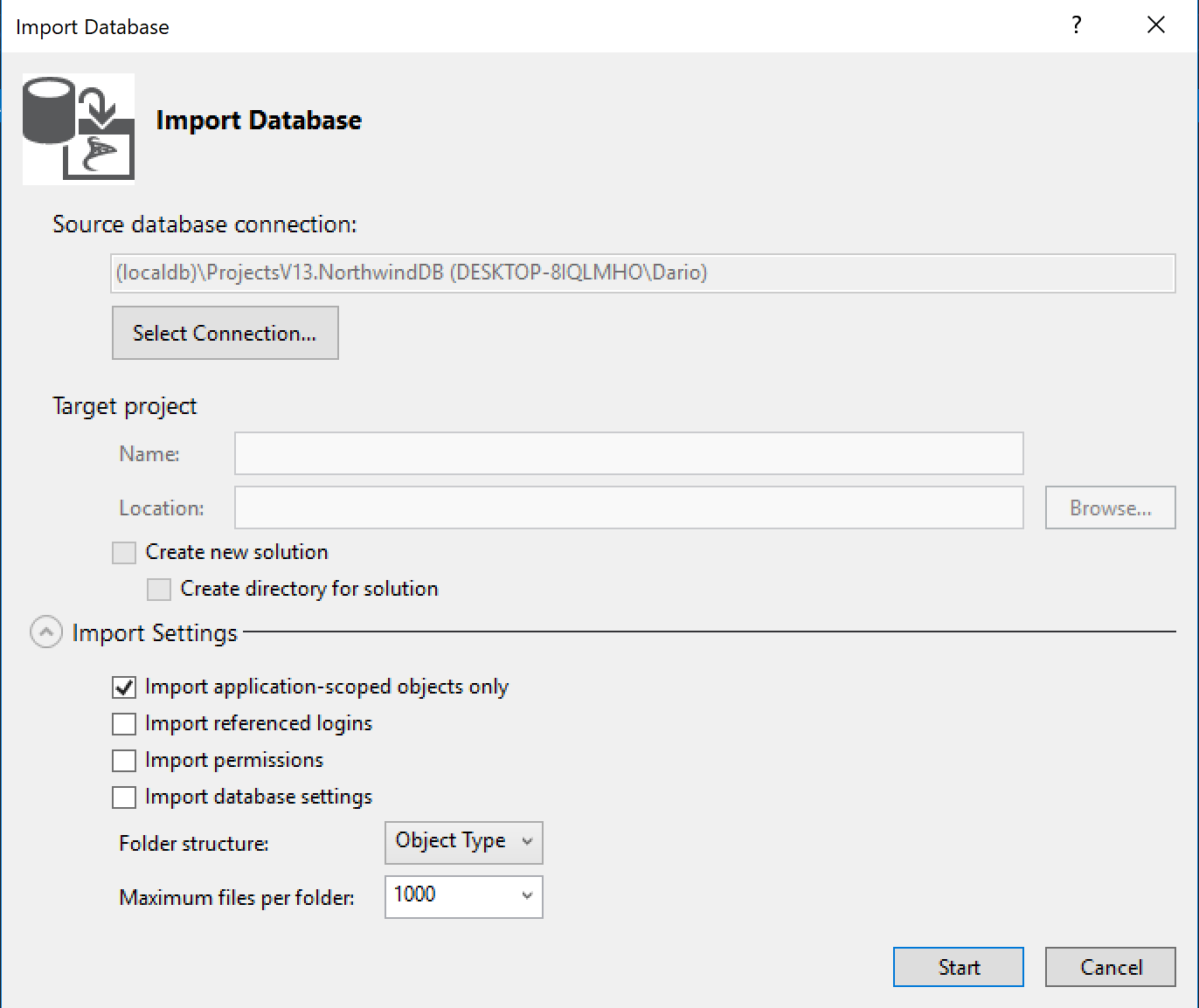
Magia! Ahora ya tenés tu base de datos lista para ser integrada a tu control de versiones.
Necesitas datos para trabajar
Ahora bien, ya configuramos una base de datos para cada dev. Pero para que esta sea realmente útil y esté lista para usar necesita algo muy importante: datos. Vamos a ver que es muy fácil crear todos esos datos a partir de una base de datos existente.
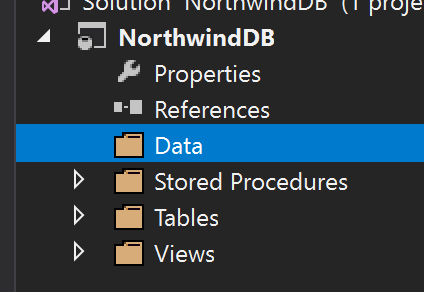
Primero, vamos a crear una carpeta llamada Data, donde vamos a guardar todos nuestros scripts.
SQL Server Management Studio tiene una herramienta muy interesante para generar scripts, y se llama… Generate Scripts!
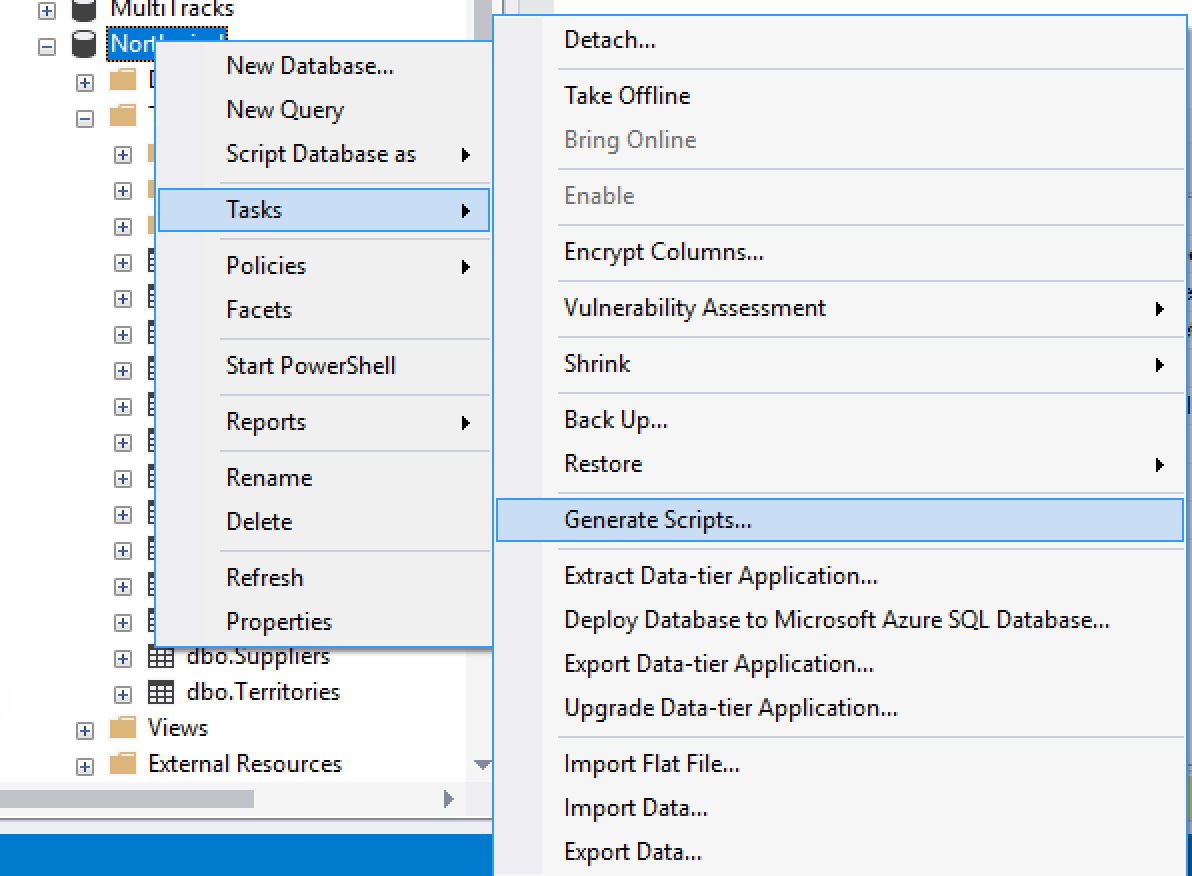
Una vez ahi, simplemente necesitamos elegir las tablas que queremos importar.
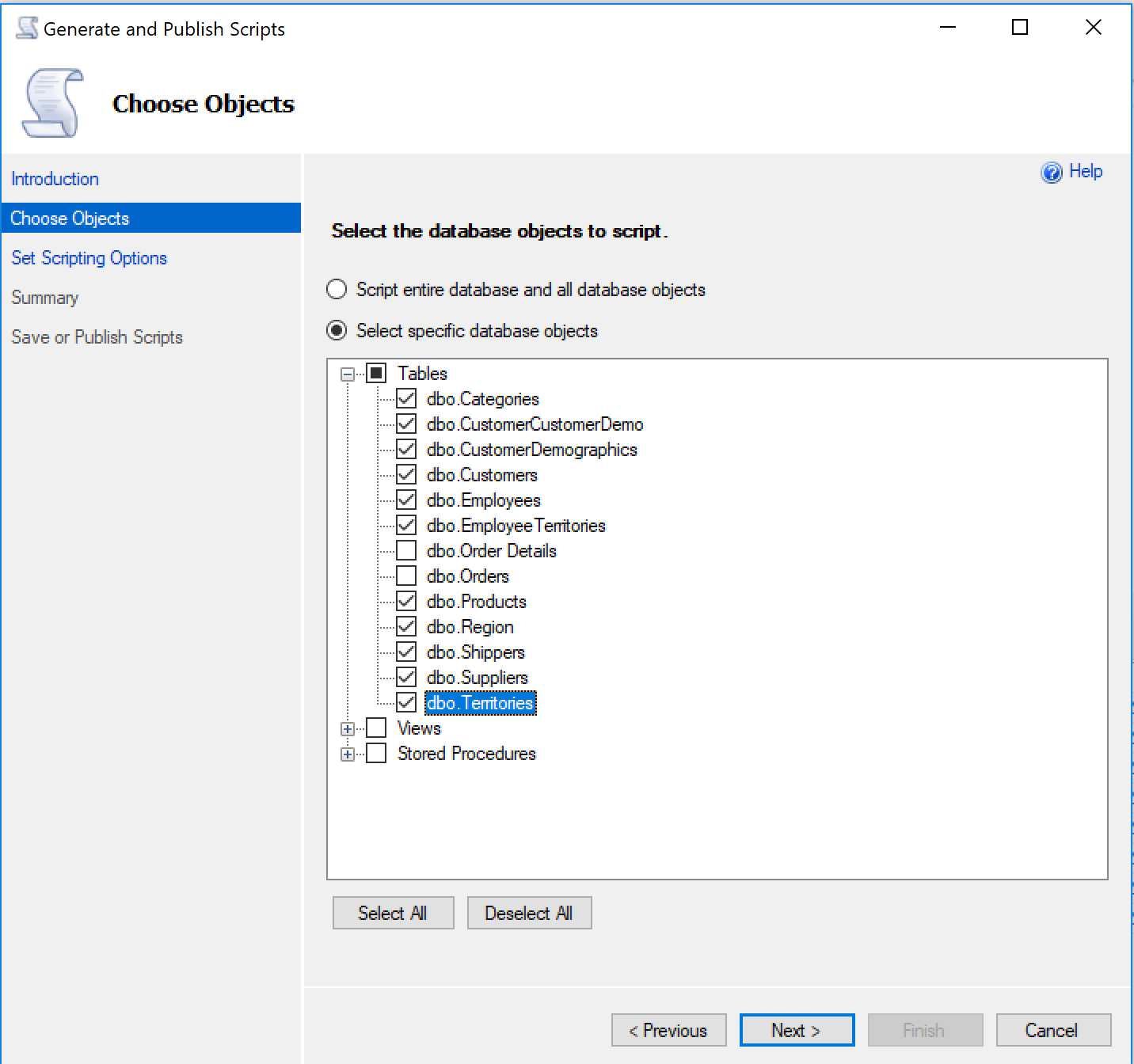
Después elegimos la ubicación. Vamos a elegir la carpeta Data que creamos anteriormente.
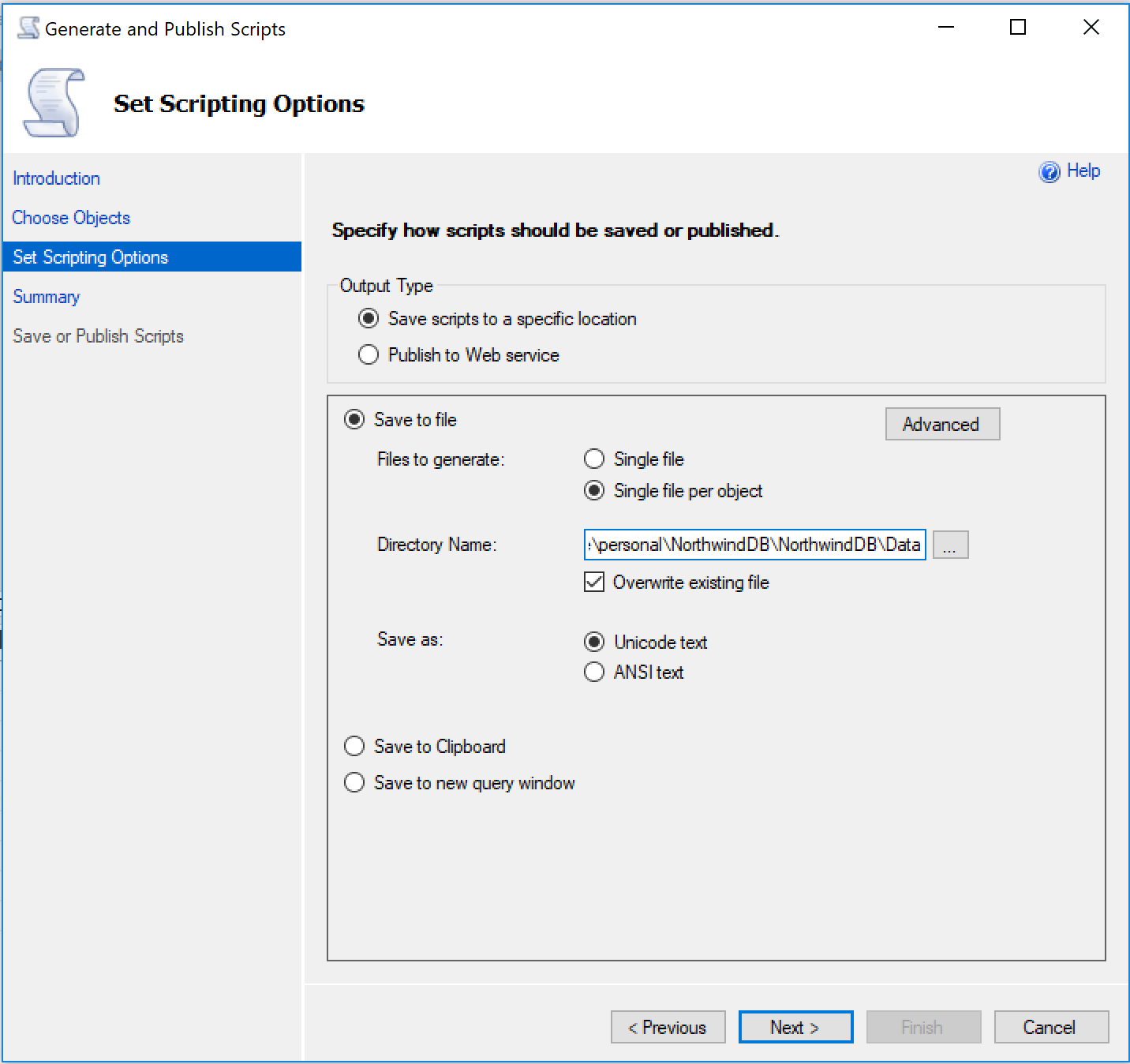
Ahora bien, necesitamos ir a la opción de Advanced para indicar que solo queremos que nos genere los inserts.
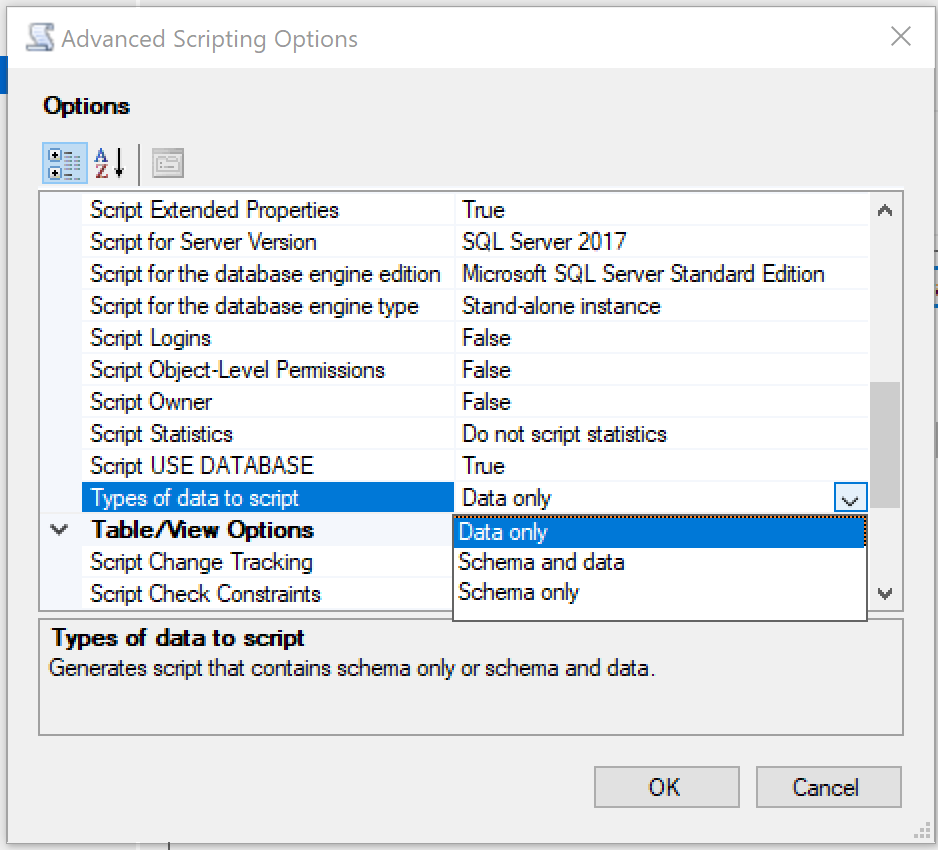
Listo!
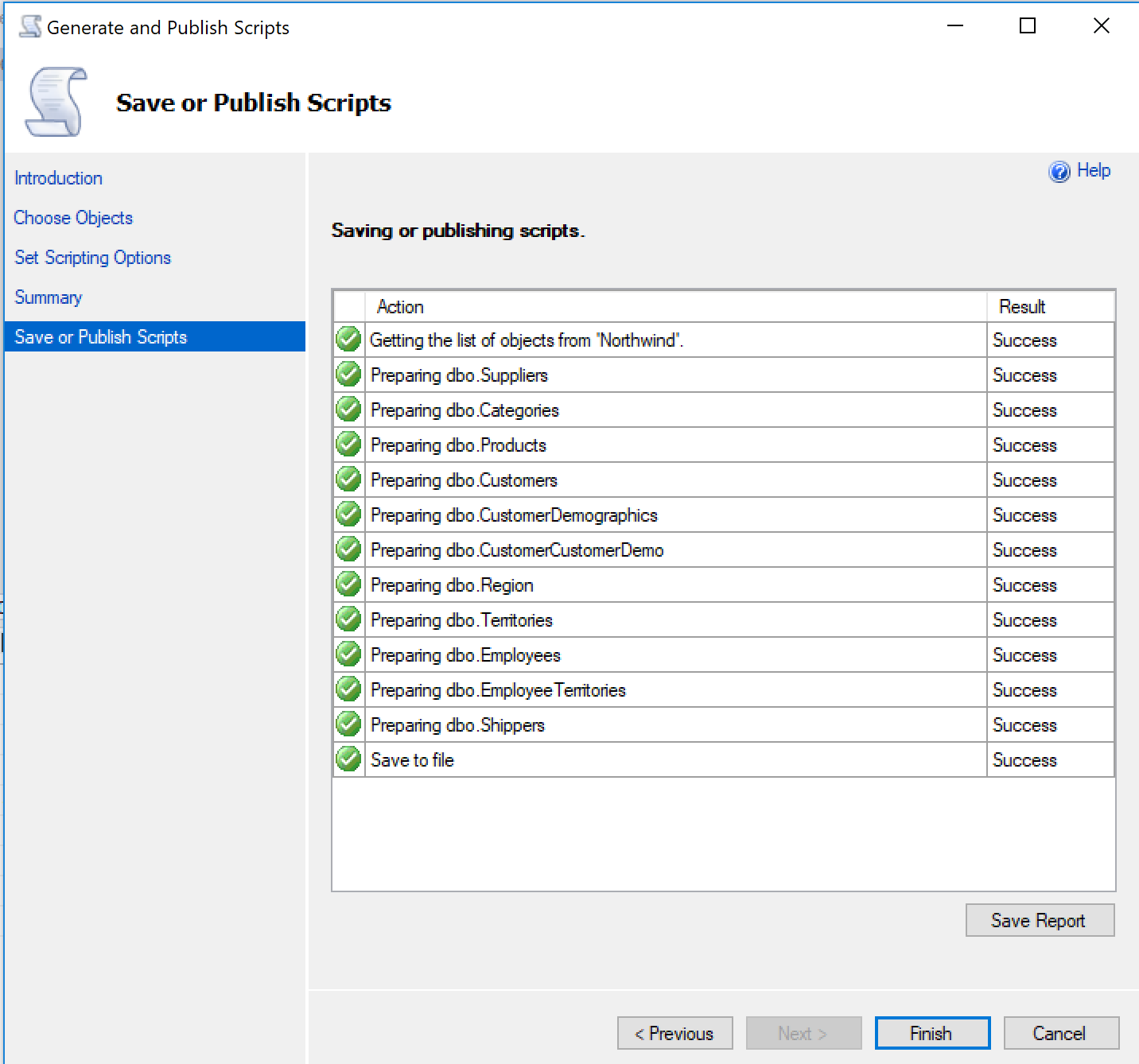
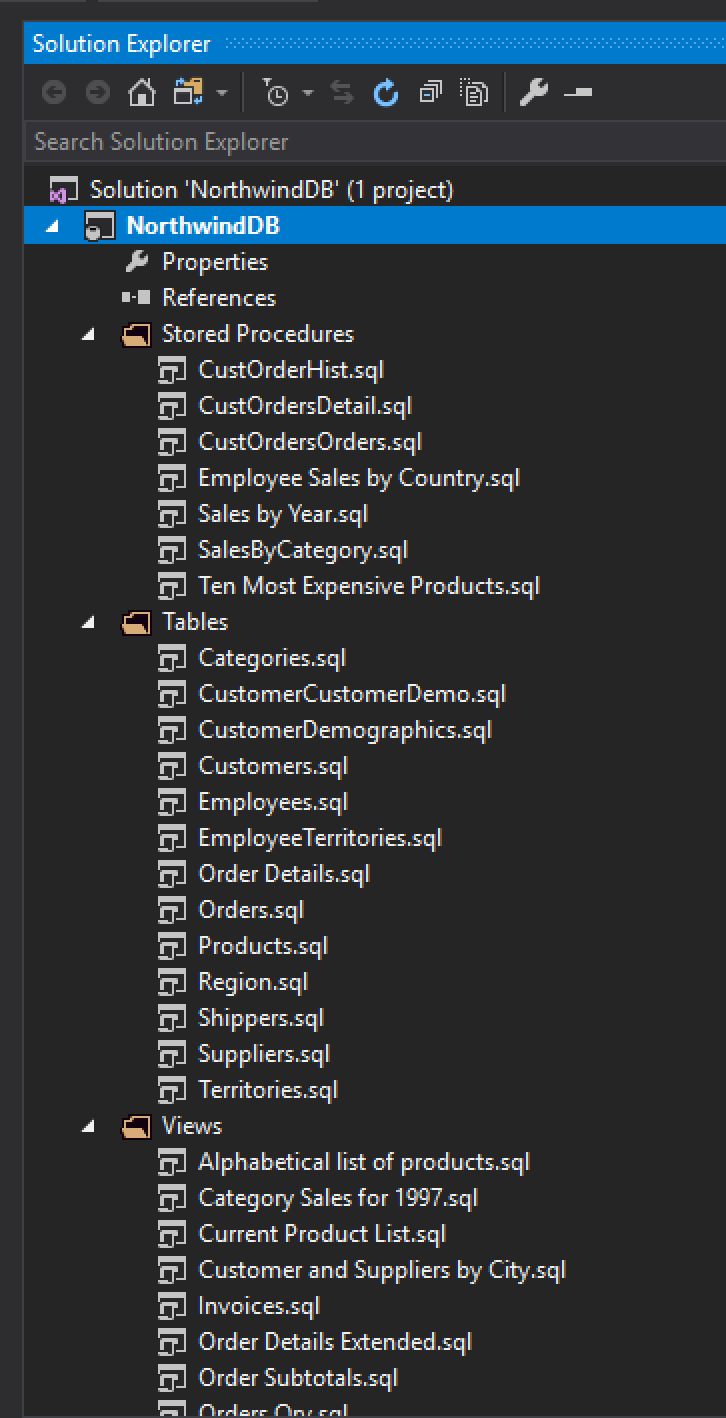
Si vamos a nuestro project de SQL vamos a ver todos los scripts que se generaron. Ahora necesitamos incluir todos esos archivos en nuestro proyecto.
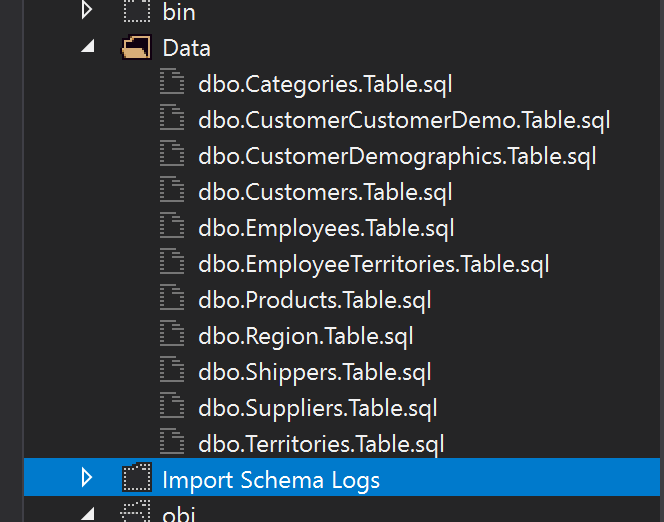
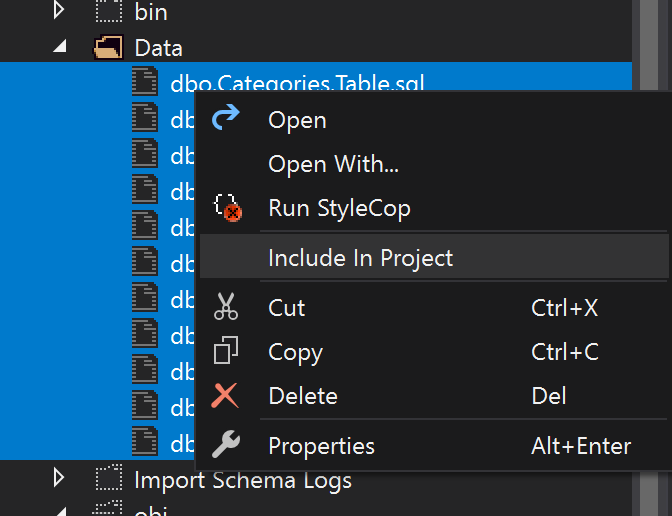
Cuando incluimos archivos en un proyecto, se agregan con el Build Action seteado en Build por default, pero como estos archivos son simplemente inserts necesitamos cambiarlos a None.
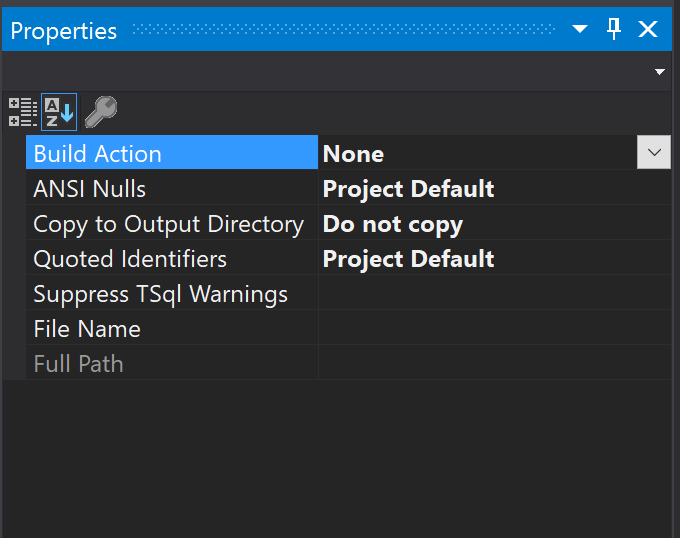
Perfecto! Pero ahora, cómo usamos estos scripts? Tenemos que crear un Post Deployment Script e incluir todos nuestros inserts allí.
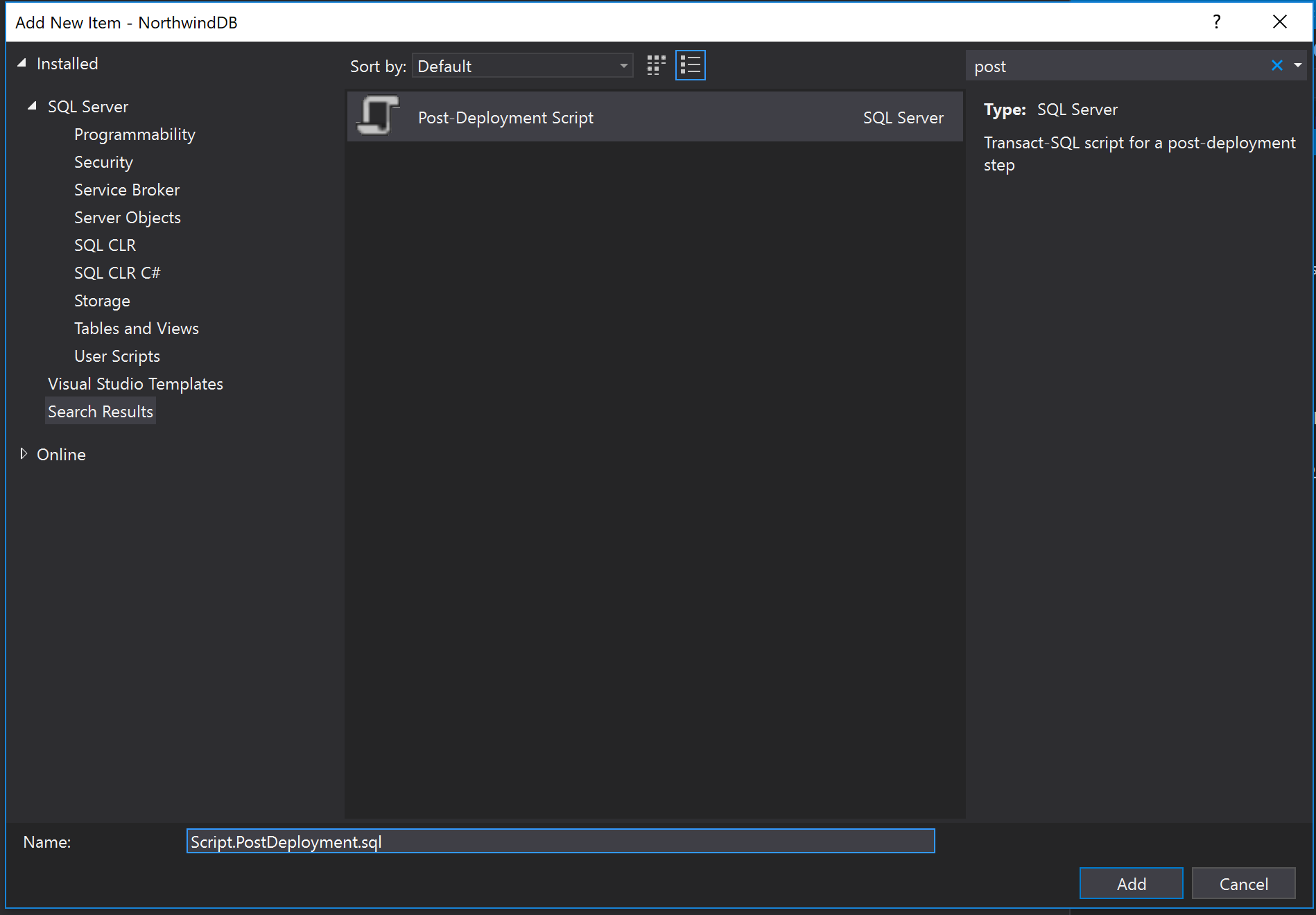
Ahora podemos completar este archivo con todos los scripts que creamos antes.
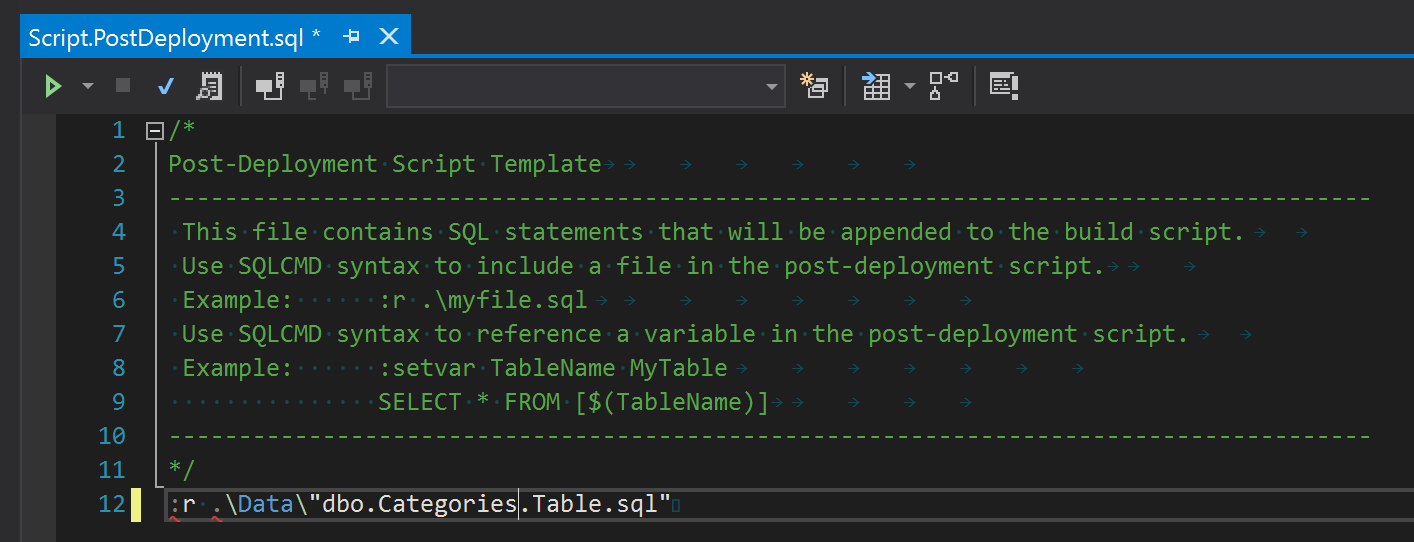
Sincronizar la base de datos
Perfecto! Tenemos un proyecto SQL, con nuestras tablas, nuestros stored procedures e incluso datos de prueba! Ahora vamos a usarlos.
Publish
Publish is la herramienta que necesitamos usar para crear la base de datos desde cero. Vamos a verla.
Una vez ahí, necesitamos elegir nuestro connection string y la base de datos de destino.
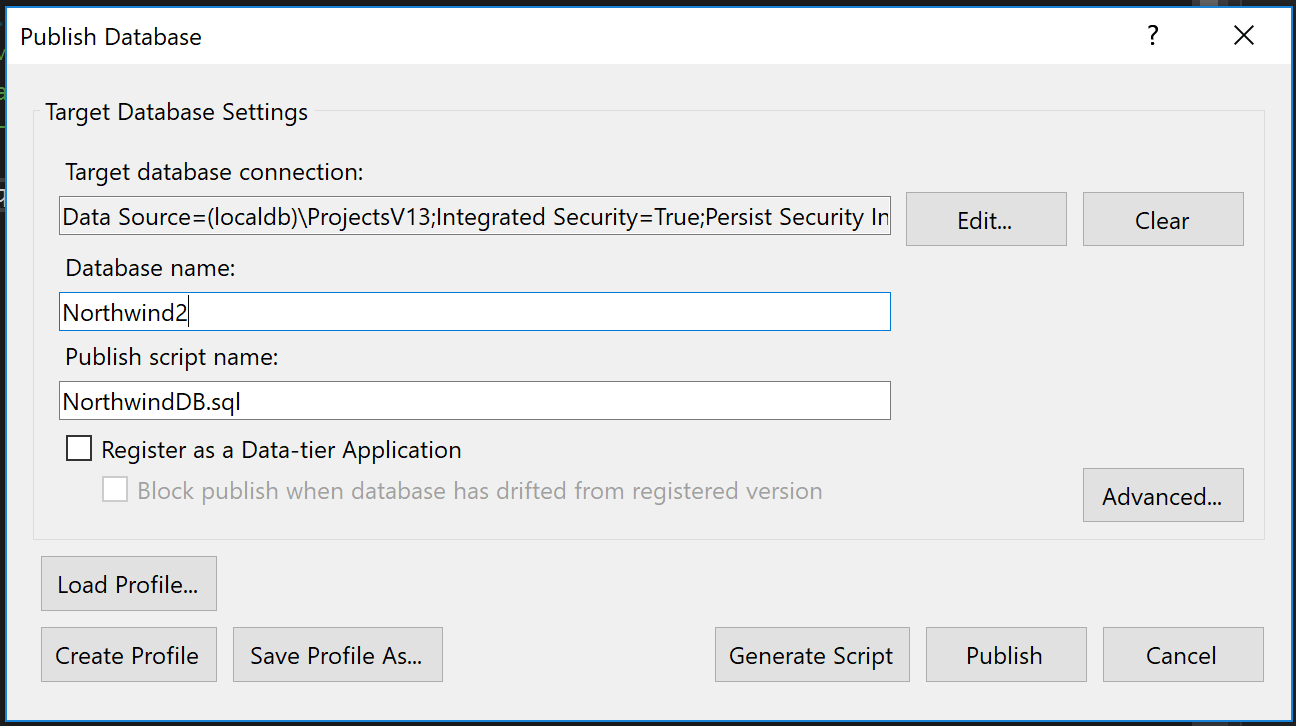
En las opciones avanzadas hay unas opciones muy interesantes, como “Always re-create database”, que lo que hace es eliminar la base antes de volverla a crear, o “Block incremental deployment if data loss might occur”, que hace que el publish falle si estamos eliminando alguna tabla, columna o cambiando algún tipo de dato.
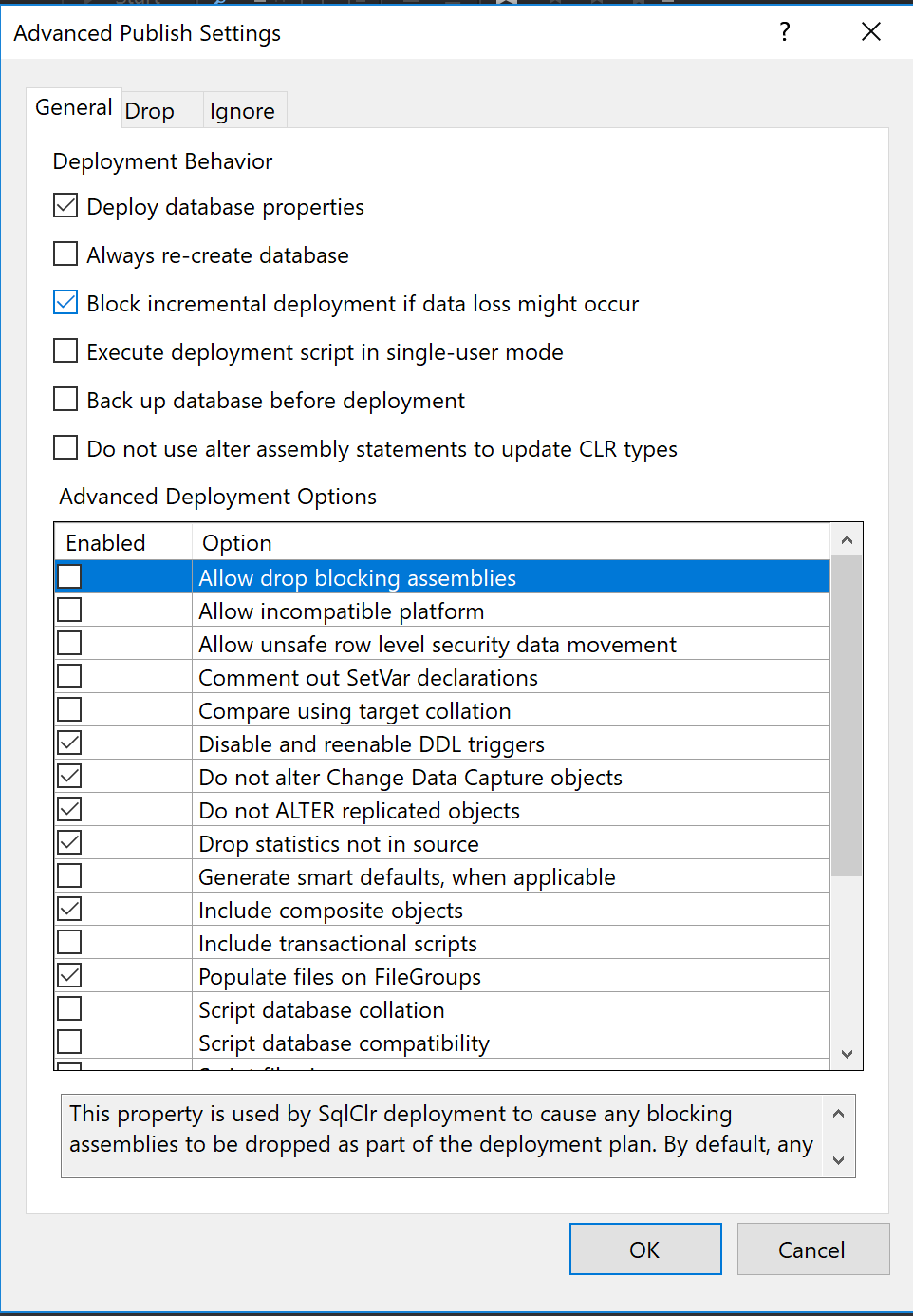
Por último hacemos click en publish y listo! Tenemos una nueva base de datos con todas nuestras tablas con datos lista para usar!
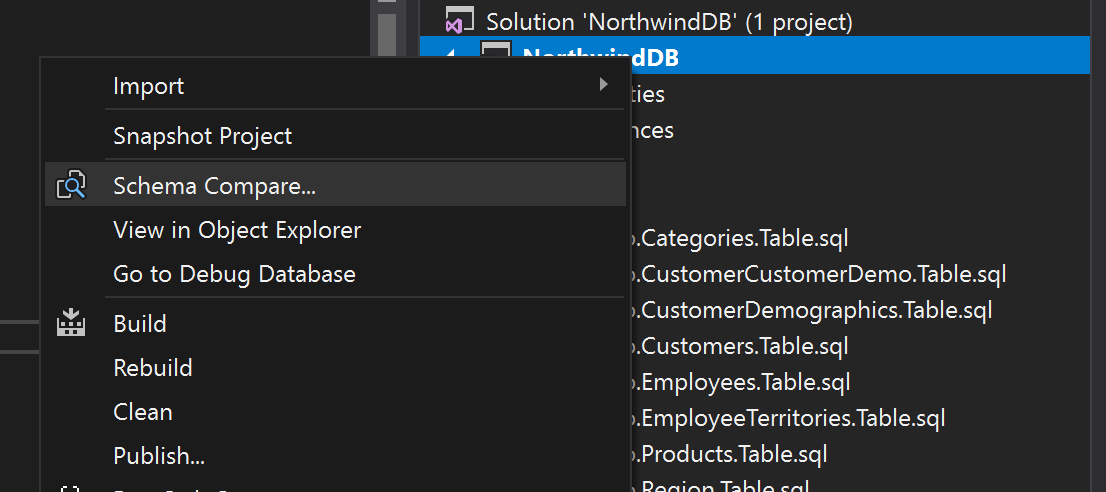
Schema Compare
Schema compare es la herramienta que se usa en el día a día para comparar y sincronizar nuestro código SQL con nuestra base de datos.
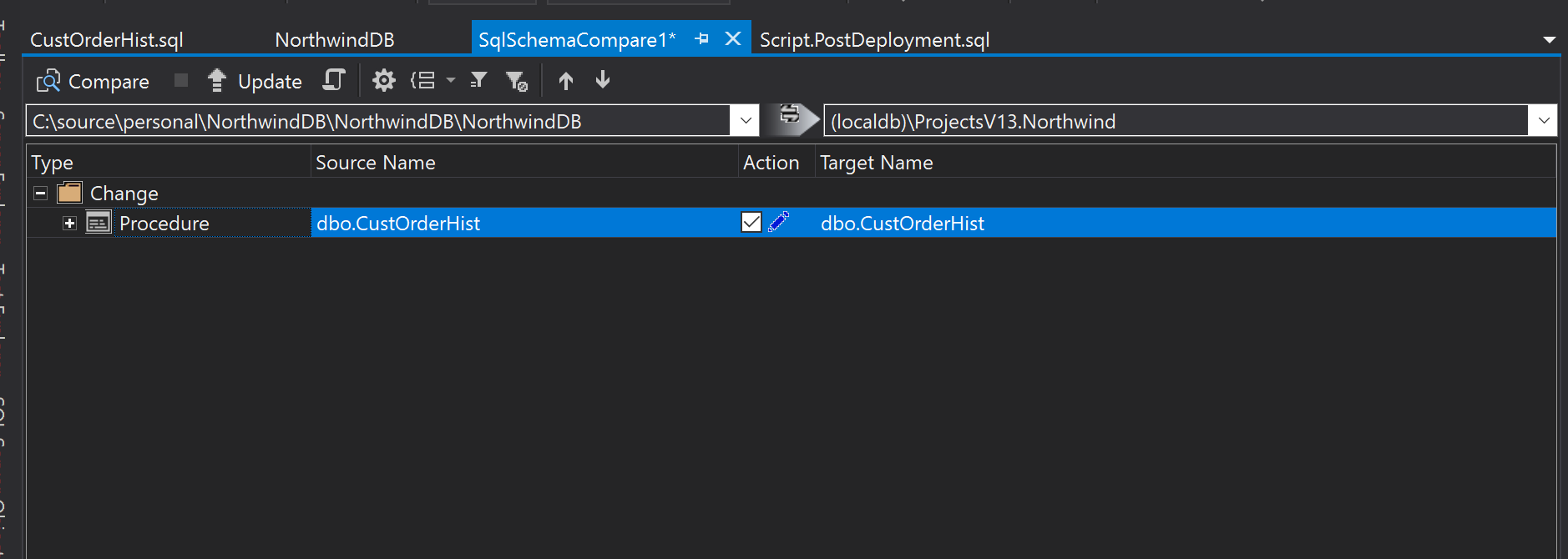
Una vez allí. No solo vamos a poder ver que objetos vamos a cambiar, sino también cuáles son los cambios.
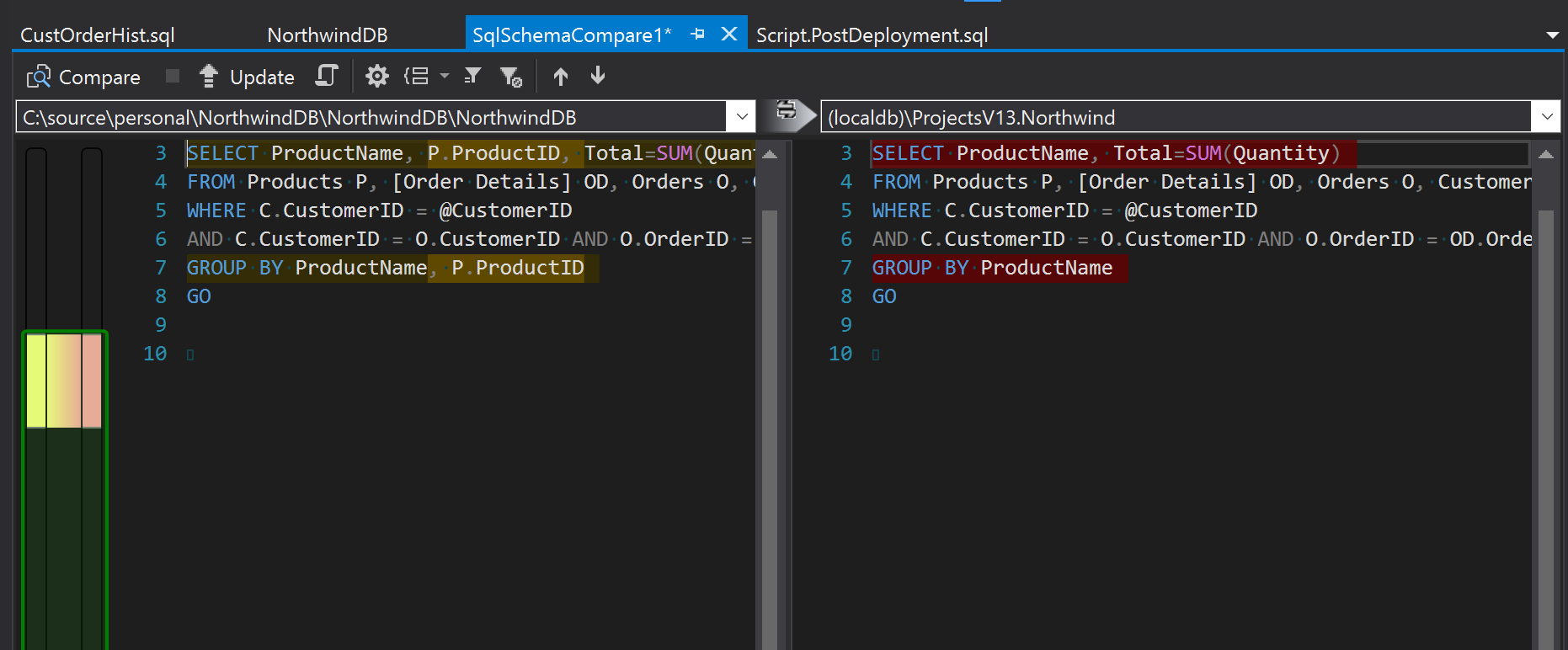
Antes de hacer click en “Update” vos podrías querer ir a “Schema compare options” y desmarcar “Block on possible data loss”. Esto va a permitir que la comparación no falle si estamos eliminando alguna columna, tabla, o cambiando un tipo de dato, cosa que puede ser común cuando se cambia de branch.
ProcUpdater
Schema compare es perfecto en lo que hace, puede crear una base de datos desde 0, crear usuarios, esquemas, detectar renombres de tablas y columnas, prácticamente todo. Pero también puede hacer lento el proceso de desarrollo. El paso de comparación puede tomar hasta 3 minutos, y el de actualización puede tomar otros 3 minutos. Si hacés eso diez veces en un día, vas a estar perdiendo una hora esperando que tu base de datos se sincronice.
Para solucionar esto, creé una aplicación llamada ProcUpdater (si, estuve muy inspirado ese día). ProcUpdater va a monitorear la carpeta “Stored Procedures” y aplicar todos los cambios que hagas instantáneamente. Incluso va a aplicar los cambios cuando cambies de branch en git. No es una herramienta perfecta, no va a aplicar cambios en tablas, pero puede ahorrarte una hora por día!
CI
Este workflow funciona perfecto si necesitas correr tests de integración en un CI. Si usás un CI corriendo en Windows, como AppVeyor, vas a poder deployar tu base de datos cada vez que hagas build de un branch. Simplemente necesitas correr msdeploy.exe. Podría ser algo así:
msbuild "NorthwindDB.sqlproj" /p:Configuration=Release /p:Platform="Any CPU"
"C:\Program Files\IIS\Microsoft Web Deploy V3\msdeploy.exe" -verb:sync -source:dbDacFx="NorthwindDB.dacpac" -dest:dbDacFx="...",dacpacAction=Deploy,CreateNewDatabase=True'
Palabras finales
Suelo decir que, la mayoría del tiempo, podemos ocultar la complejidad pero no eliminarla completamente. Si tu proyecto usa un montón de stored procedures, no vas a ser capaz de eliminar esa complejidad (y ni siquiera hablamos de manejar entornos de Staging!), pero espero que estos consejos te ayuden a acelerar tu proceso y a hacer que tu equipo sea más productivo.
No dejes de codear!